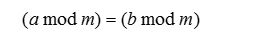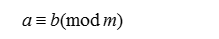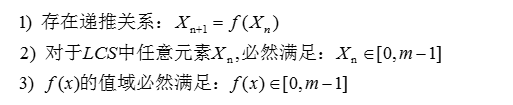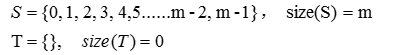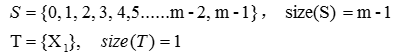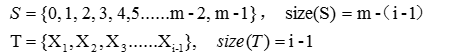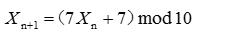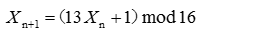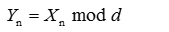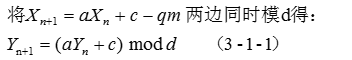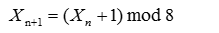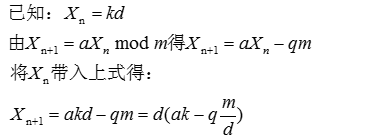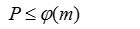本文旨在简单探索线性同余发生器的一些原理和特点,很多思路借鉴于TAOCP,如果想要深入的探索这方面的知识,建议直接阅读原著。
一、公式化定义与线性同余序列的周期在离散数据及其应用中,如果
那么,称a模m同余b(或者称模m时,a等价于b),可以记为
而线性同余式就可以这样表示:
线性同余发生器与上面的线性同余式多少有一些关系。
2.1 公式化定义
按照The Art of Computer Programming,Volume 2[1]中3.21. The Linear Congruential Method的思路,线性同余发生器(LCG:Linear Congruential Generators )可以采用如下公式化定义:
其中:
模数m和系数a是这个公式中最重要的参数,如何合理的选择这两个参数决定了其产生的线性同余序列(LCS:Linear Congruential Scquence):<X>质量的优劣(<X>=X1,X2,X3..Xn...)。
常数c可以为0,也可以不为0。通常,如果c=0,那么(2)式也称作乘法线性同余发生器(MCG:Multiplicative Congruential Generator),如果c非0,(2)式,则称作混合线性同余发生器(Mixed Linear Congruential Generator)。
X0称作初始值,也就是所谓的种子seed。
2.2 线性同余序列的周期
如上的线性同余发生器产生的线性同余序列必然会存在一个周期P。在TAOCP中,作者以一个练习的方式提出了这个问题(exercise 3.1-6)。以下通过一种简单直白但不严谨的推理来解释这个问题。
将上述线性同余公式抽象为一个函数f(将Xn映射为Xn+1),这个函数具有自封闭特性。不难发现,实际上存在以下已知条件:
定义两个集合:S和T。初始状态下,集合S包含了从0到m-1所有的m个元素,集合T是一个空集。
现模拟产生LCS的过程,以任意值X0为参数,产生第一个伪随机数X1。其值必然属于集合S,此时将X1从集合S移动到集合T。
以X1为参数,产生第二个伪随机数X2=f(X1),此时,X2有可能属于集合S,也有可能属于集合T。
1)如果X2属于集合S,那么此时还没有产生一个周期;
2)如果X2属于集合T,此处也就是刚好等于X1,那么此时一个周期产生,周期P=1。
更一般地,假设在生成X1到Xi-1过程中,每个数都是在集合S中找到的,则每个数都从集合S中移动到了集合T,此时两个集合的状态为:
然后生成Xi时,
1)如果Xi=f(Xi-1)在集合S中,则未能产生一个周期;
2)如果Xi=f(Xi-1)在集合T中,则一个周期产生,此时周期P<=i-1。
当然周期P也有可能等于m,也就是集合S最终为空集,集合T容纳了0到m-1的所有元素,且f(Xm)=X1。
因此,从以上推理不难得知,LCS必然存在一个周期P,且P<=m。
进而不难推断:
1)如果某LCG产生的随机序列的周期P小于m,则选取不同的初始值X0产生的LCS可能有不同的周期。
2)如果其周期P=m,则即使选取不同的X0,产生的这些LCS具有相同的周期且必定为P。
例如,对于下面发生器:
如果以初始值X0=12产生随机序列为:
7,6,9,0,7,6,9,0,7,6,9,0,7,6,9,0......
如果以初始值X0=13产生随机序列则为:
8,3,8,3,8,3,8,3,8,3,8,3,8,3......
但是,对于如下的发生器:
无论选取何值为种子产生的随机序列,其周期都是16。
二、关于参数选择构造一个表现良好的线性同余发生器并非易事,不但考虑其产生的随机序列的周期、随机分布特点,还要考虑计算的效率。
在参数的选择方面,最关键的就是modulus和multiplier的选择。
3.1 modulus选择
modulus应该尽可能大,这样才有可能产生较长的周期。如果计算机的字长为w位,TAOCP中推荐,应该取m=2^w,或者m=2^w+1,或者m=2^w-1,也可以取小于2^w的最大的素数,在论文TABLES OF LINEAR CONGRUENTIAL GENERATORS OF DIFFERENT SIZES AND GOOD LATTICE STRUCTURE[2] 中就采用了这种m值选取的方式。
通常而言,如果取m=2^w,则利用位运算往往会使计算过程更加方便和高效,但是会存在一个问题:产生的随机序列中各元素的低比特位的随机性并不是很好。
简单的解释是,当m=2^w时,对于一个s位的整数Z,Z模m的结果实际上就是Z的比特位中右边的s-w位的结果。
作者在原文中用了比较形式化的描述来说明这个问题:
假设d是m的一个因子,q为某一整数,令Yn满足如下关系:
然后进行如下变换:
不难发现由公式3-1-1实际就是一个线性同余发生器,产生的随机序列也具有周期,但是其周期小于等于d。
这里的<Y>序列实际上对应了原线性同余序列<X>的低位字节,可以将序列<Y>理解为是将<X>的低位单独抽取出来组成的一个序列。例如如果d=2^4,则序列<Y>的周期最大也就是16,对应了序列<X>中各个元素的低4位比特位的周期最大是16,显然低位的随机性并不是很好。正是由于这个原因,有些平台的实现会丢弃这些随机性不好的低比特位,截取高比特位以取得一个比较好的随机性效果。大多数应用场景中,低比特位并不会对最终用途产生影响,因此选取m=2^w基本能够满足要求,实际上很多平台也确实都是取m=2^w。
如果m取2^w+1或者m=2^w-1,则不会产生上述问题。
3.2 multiplier的选择
multiplier的选择推理过程比较复杂一些。一般来讲,应该使LCS的周期尽量长(最长为m),然后只使用一个周期内的元素,但是周期长的序列可能并不具有很好的随机性。
比如如下的线性同余发生器:
以初始值X0=3产生随机序列的结果:
4,5,6,7,0,1,2,3,4,5,6,7,0,1,2,3,4,5,6,7,0,1,2,3......
可见,以上序列的随机性表现很糟糕。
在TAOCP中证明了如下定理,按照如下方式来选定系数a可以产生最大周期为m的LCS。
以上定理表明当c不等0时(c与m互质当然就不可能等于0),有可能产生周期为m的LCS。
另一方面,当c=0时,也即:
是否也有可能产生周期为m的LCS呢?答案是必然不可能。
一个简单的反证法:
如果c=0时,产生了周期为m的LCS,那么0必然在这个序列中,但是如果0在序列中,必然会导致LCS退化成全0的序列,因此原命题必然不成立。
从另一个角度考虑:
考虑d是m的一个因子,且Xn是d的倍数,也即Xn=kd,其中k为某整数。于是有如下推导:
由此可知,Xn+1也是d的倍数,同理,后面的Xn+2,Xn+2也是d的倍数,现在这样的序列也不是一个号的序列。所以如果要求序列中各个元素分别与m形成互质关系,因此这样的序列的元素个数实际就是欧拉函数对m求值,也即:
简单总结几点即是:
1)模数m应该尽可能大,通常至少大于2^30,为了计算效率,通常会结合计算机的字长考虑选取m的值。
2)如果m选取为2的幂,也即m=2^w,则选取的a通常应该满足a模8等于5。
3)当参数m和a的选定比较合理时,对于c的选择约束性不是很强烈,但要保证c与m互质。例如c可以选择1或者11。
4)种子seed应该是随机选取的,可以将时间戳作为种子。
因为Xn的低有效位的随机性表现并不是很好,所以在对Xn的随机特性比较敏感的应用场景中,应该尽量采用高比特位。事实上,更应该将值Xn/m视为0到1之间的均匀分布,而不是直接将Xn视为0到m-1之间的均匀分布。所以,如果希望产生0到k-1之间的均匀分布伪随机数,应该采用kXn/M的方式。 在具体构造一个LCG时,不仿参考TABLES OF LINEAR CONGRUENTIAL GENERATORS OF DIFFERENT SIZES AND GOOD LATTICE STRUCTURE[2]中的表格来选取参数,该文中针对MLCG和LCG给出了若干可供选择的参数m和a的值:针对MLCG,m取小于2^w的最大质数;针对LCG,m取2^w。